
人間は毎日音声を用いてコミュニケーションを行っています。どんなにテクノロジーが進歩しても、 人間の生活における音声コミュニケーションの重要性は変わりません。 人間の音声生成は、肺と喉頭部にある声帯と呼ばれる柔らかいヒダ状の部位、そして、舌・口蓋・口唇・鼻腔といった声道の複雑な動作によって実現されています。 肺からの呼気によって声帯が振動することで音源を生成しています。 また、一部の子音では、口腔内での狭めや瞬間的変化によって生じる乱流が音源となっています。 これらの音源音は、口腔の形状に応じて様々な共鳴が生じ変化します。これが声として発声されるのです。 このように、複雑なメカニズムであるためそのメカニズムや制御にはまだまだ未解明な点が多くあります。
また、現代社会においては音声合成は案内放送など、多くの場面で活躍しています。 ロボットにおいても音声を用いたインタラクションは数多く試みられています。 しかし、これまでは音声をスピーカーで合成する手法を用いることが多く、現実に人間と同じ方法で音声を生成する方法は十分に検討されてきませんでした。 しかし、本当の人間と対話しているような感覚を与えるためには、人間の発声メカニズムを再現することは有効な手段です。 ここで、音声科学の研究成果とヒューマノイドロボットの技術を組み合わせることで、 Waseda Talkerシリーズではこれまでの機械モデルで困難であった多様な音声の生成が可能となりました。 さらに、WT-5(Waseda Talker No.5)より、人間の声帯や舌の形状を3次元で再現することで、 より人間に近いモデルによる音声生成の再現に取り組んでいます。
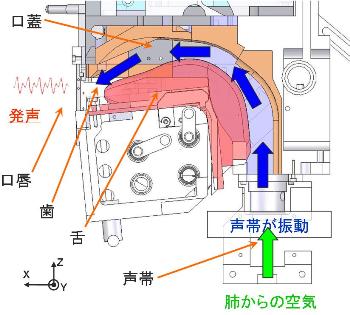
人間の発話メカニズムの解明と人間に近い音声生成の実現を目的として2009年にWT-7R(Waseda Talker No.7 Refined II)を開発しました。 WT-7RIIは人間と同じ発話メカニズムによって音声生成を行うため、肺・声帯モデル、顎・舌・口蓋モデル、口蓋帆・鼻腔モデル、口唇モデルからなっています。 また、このロボットにおいては音響的な観点から人間と同サイズでモデルを構築しています。 自由度構成は、発声器官の声帯 が5自由度、肺が1自由度、調音器官である舌が7自由度、口蓋帆が1自由度、 口唇が5自由度、 顎が1自由度の計20自由度となっています。
肺は、左右二つのシリンダからなり、一つのACモータにつながれたボールねじによりシリンダを上下させ空気流量を制御しています。 なお、空気を吸う際は声帯機構の肺側に設けられた吸い込み弁から空気を吸い込みます。
声帯は熱可塑性エラストマー(セプトン)を用いて、人間の声帯の形状を再現した一体型モデルを用いています。 この素材は、200度の加熱をするのみで成形が可能であり、シリコンに比べて大きな伸びと破れにくさを有しています。 この声帯モデルは、人間の通常(モーダル)音声生成時の声帯振動の特徴である、上下で位相差を有する振動を再現することが可能です。 また、様々な音声を生成するため、声帯部には振動部(声門)の張力調整、声門の開閉、 および振動部の下側を押さえる機構が設置されています。
舌部は人間の舌の変形を再現するために、顎および剛体リンクに3次元で成形した軟素材のカバーをかぶせることで成形しています。 設計においては人間の母音発声時のMRI(Magnetic Resonance Imaging)画像を解析した結果から、 舌先・舌前部・舌体の3つの部分の変形を再現することを目的とし、それぞれ3自由度、2自由度、2自由度の合計7自由度の剛体リンクを用いています。 舌内のスペースが限られるため、後頭部に設置したDCモータからタイミングベルトで動力を伝達して制御しています。
口唇部は、人間の口唇の形状および断面積を再現するために、人間の「う」発声時の口唇形状で成形した軟素材を斜め上、 斜め下および真下の5方向から押し引きする機構となっています。 この機構により、5母音発声時の口唇形状や、「ぱ」のような子音の完全閉鎖を再現することが可能です。


WT-7RII(Waseda Talker No. 7 Refined II)では、2に述べた機構により母音および子音の生成を実現しています。 WT-7RIIの連続発話時の舌形状の制御方法には、音素情報を用いるものと、人間の発声データを用いるものの2種類があります。
音素情報を用いる場合には、あらかじめ各音素(母音や子音)に対応するロボットパラメータを決定します。 そして、それぞれの音素の時間(母音時間・子音時間)および遷移時間を決定し、 遷移時間中のパラメータは両端の音素のパラメータから三角関数補完により決定します。 人間の発声データを用いる場合には、 まずEMA(ElectroMagnetic Articulometer)と呼ばれる人間の舌上に張られた小さなコイルの空間上の位置を測定することのできる装置を用いて 人間の発声時の舌変形を計測します。 その後、人間とロボットのサイズの違いを補償し、ロボットにおける舌目標軌道を生成します。そこから、逆運動学によって舌の制御パラメータを決定します。
これら二つの方法はそれぞれに利点と欠点あります。 前者の方法は、一通りの子音と母音のロボットパラメータを決定すれば、どんな文章・単語でも発声が可能という利点がありますが、 実際の人間の舌形状と異なり、無駄な動きも多いため、すばやい発声を行うことが困難です。 一方の人間のデータを用いる方法を用いると、人間の舌の動かし方そのものを再現することができるため、無駄の少ないすばやい発声を行うことができます。 しかし、EMAデータが存在する発話のみしか発声することができず、さらにEMAの計測は装置が高価なため、 限られた場所でしか行うことができないという問題があります。
 |
 |
|
音素情報を用いた 「さしすせそ」発声時の舌の動作 MPEG1 0.92 MB |
調音データによる 「さしすせそ」発声時の舌の動作 MPEG1 0.63 MB |
 |
 |
 |
 |
|
「あいうえお」 (音素情報) MPEG1 1.69 MB |
「あいうえお」 (調音データ) MPEG1 0.72 MB |
「さしすせそ」 (音素情報) MPEG1 1.37 MB |
「さしすせそ」 (調音データ) MPEG1 0.42 MB |
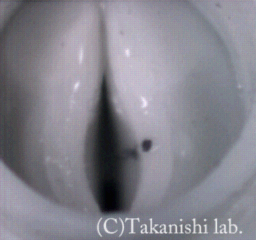
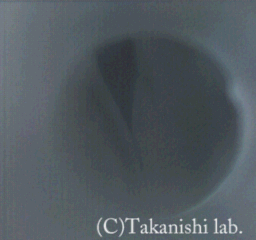
WT-7RIIの声帯モデルは、人間の声帯に近い振動を行うことができるため、人間の様々な声帯振動の解明に活用できると考えています。 われわれが通常の会話に用いている音声はモーダル音声と呼ばれています。 一方、極めて低い周波数の音声を発声させようとするとパルス状のバタバタした音声になることがあります。 これをフライ発声とよび声帯振動の様式の違いによるものといわれています。同様に空気の抜ける音がする気息性発声という振動の様式もあります。 これらの発声時の声帯振動の再現にも取り組みました。
ここでは、モーダル音声、気息性発声とフライ発声時の声帯振動の様子を高速度カメラ(1000[fps])で撮影したビデオを紹介します。 気息性発話では、声帯の一部が常に開いていることが確認でき、フライ発声では二重振動になっていることが確認できます。
 |
 |
 |
| モーダル(通常)発声 MPEG1 0.99 MB |
気息性発声 MPEG1 0.34 MB |
フライ発声 MPEG1 1.26 MB |
人間形発話ロボットは、自然な人間−ロボットインタラクションの実現や音声生成・制御メカニズムの解明のための実験装置、 さらには耳鼻咽喉疾患の治療法のテストなど様々な用途への活用が考えられます。 これらの用途に実際に活用していくためには、さらに人間に近い機構を実現することが必要であると考えています。
本研究は、2003年度まで科学技術振興機構 (JST) 戦略的創造研究推進事業 (CREST)の援助を受けて行われ、2004年度から科学研究費補助金の援助を受けて行われています。 研究に協力して頂いた、(株)クラレ、ATR(人間情報科学研究所)の皆様に感謝致します. 3DCADソフトウェアをご提供して頂いたソリッドワークス・ジャパン株式会社、テフロン被覆ワイヤを 提供して頂いた中興化成株式会社に感謝致します。
 科学技術振興機構(JST)
科学技術振興機構(JST)