
In human communication, voice have very important role. However, not all of human speech production and control mechanism is clarified. Human speech mechanism have complex movement by the vocal organs and the vocal tract; the former is the lungs and the vocal cords in larynx, the latter is consisted of the tongue, the palate, the nasal cavity and the lips.
In the human speech mechanism, human vocal cords, which are thin folds on the larynx, generate sound as they are vibrated by airflow from the lungs. This source sound enters the vocal tract, which is a resonance tube constructed by the tongue, palate, nasal cavity, and lips. The vocal tract articulates the source sounds into vowels and consonants. This basic theory has been clarified; however, the control of the complex movement of speech organs and detailed phonemes in speech production are still unclear.
For clarifying human speech, mechanical models are superior method. The speech production is acoustic phenomena, so it is difficult to simulate accurately by computer simulation. From few centuries ago, peoples developed several mechanical models of speech organs, however, these are simple mechanism and difficult to simulate the movement. We started to develop anthropomorphic talking robot Waseda Talker series to combine the speech science and humanoid robot technology, and realized speech production of various vowels and consonant sounds. Additionally, from WT-5(Waseda Talker No. 5), we started to develop models have three dimensional vocal cord and vocal tract models and reproduced more human-like speech production mechanism.
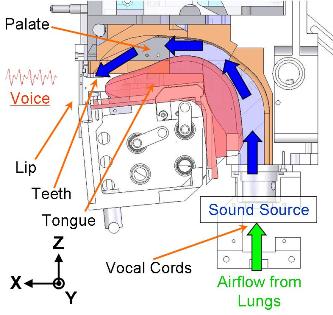
We developed WT-7RII(Waseda Talker No. 7 Refined II) in 2009, which have human-like speech production mechanism. WT-7RII are consisted of the mechanical models of the lung, the vocal cords, the tongue, the jaw, the palate, the velum, the nasal cavity and the lips. These mechanical models are designed based on human and they have same size as adult male of human to have similar acoustic characters. The mechanism have 1 DOF(Degrees Of Freedom) in the lungs, 5 DOF in the vocal cord model, 1 DOF in the jaw model, 7 DOF in the tongue model, 1 DOF in the velum model and 5 DOF in the lips model: the total DOF is 20.
Lung model are constructed by two piston cylinders. Outlets of two cylinders are connected to the vocal cord model. The airflow rate can be controlled by changing the moving velocity of the cylinders.
Human vocal cords are vibrated by airflow from the lungs, generating the sound source of the voice. We developed the vocal cord model using Septon by Kuraray Corp, based on the human biomechanical structure. The vocal cords have control mechanism, consisted of a pair of discs that are attached directly to the vibrating points. The pushing mechanisms are also set on the lower side of the vocal cords to stabilize vocal cord vibration.
The tongue mechanism was designed based on the deformation of the human tongue. In human tongue analysis, the deformation of three parts on the tongue is important. We should control three parts separately. We designed the tongue mechanism by three parts (the tip, the blade and the body) of the rigid link mechanisms for WT-7RII. The mechanism for the tip of the tongue is a 3 DOF parallel link that controls the position and posture of the tip. The vertical deformation is reproduced mainly by the jaw mechanism. However, to allow independent movement on the tongue tip, we add 1 DOF on the parallel link. The tongue blade and the tongue body are each reproduced by a set of 2 DOF slider-crank links. Each slider-crank mechanism controls the link length and the link gradient.
The lips are designed to reproduce the shape and open area of human lips. The mechanical lips are made of soft material and are connected by a vise mechanism to five direction links and one fixed point (upper lips). With these mechanisms, the lips can produce the shape of five Japanese vowels (/a//i//u//e//o/) and total closure (/p/).


WT-7RII(Waseda Talker No. 7 Refined II)could produce Japanese vowels and consonant sounds by the mechanism. In the continuous speech we have two methods to construct speech trajectory. One method is made by preprogrammed parameters of each phoneme. When producing continuous speech, the trajectory includes the static phoneme phase and the transition phase compensated by sine function. Another method is using human articulatory data. To collect the data, we use EMA(Electro Magnetic Articulograph) system, which have small coils to attach on the tongue surface and can obtain position information.
Each method have advantage and disadvantage.
In the former method, once we decide the parameters of each phoneme, we can produce every words and sentences.
However, the movements are not efficient. The motors should move very fast, if the robot speech fast.
It became the limitation to realize the human speed speech.
Latter method has opposite characteristic. We can produce human-like smooth trajectory, however, the word list is limited by
the number of human articulatory data. And the EMA system is special and difficult to correct various articulatory data.
 |
 |
|
Tongue Movement of /sasisuseso/ with Phoneme Based Control MPEG1 0.92 MB |
Tongue Movement of /sasisuseso/ with EMA Data Based Control MPEG1 0.63 MB |
 |
 |
 |
 |
|
/aiueo/ Phoneme Based MPEG1 1.69 MB |
/aiueo/ EMA Data Based MPEG1 0.72 MB |
/sasisuseso/ Phoneme Based MPEG1 1.37 MB |
/sasisuseso/ EMA Data Based MPEG1 0.42 MB |
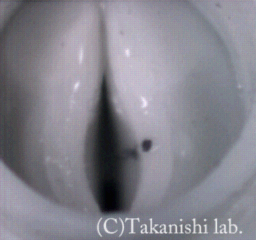
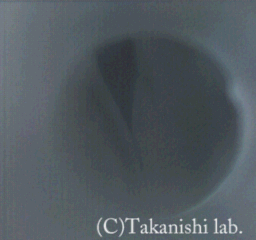
The vocal cord model of WT-7RII can be applied to the clarifying various vibrations of the human vocal cord. Modal voice is a normal phonation setting and is mostly used in the human voice control. The vocal code vibration is characterized by a periodic vibration having the opening phase and the perfect closing phase. Breathy voice is characterized by the sound of voice mixed with friction noise which generated by airflow turbulent. The vibration is characterized by incomplete closing phase as compared with that of the modal voice. The breathy voice is associated with less laryngeal effort and slight friction sound. Creaky voiced is often observed at the end of sentence utterance. This voice is characterized by an extremely low pitch vibration or double pitch vibration. In The sound pitch with the double pitch vibration is perceived as a half of the single (normal) pitch vibration.
These movies are the modal, the breathy and the creaky vibrations of vocal cord model taken by high-speed camera(1000[fps]). The vibration movie of the modal voice is characterized by the phase difference between the lower and upper parts. From the breathy vibration cycle, it is shown that the upper side of the glottis is kept open, even in the closed phase of the vibration. The creaky vibration shows a double pitch pattern and the glottis is barely opened once it is in the vibration cycle; therefore, the closing interval is much longer than the opening interval.
 |
 |
 |
| Modal Voice MPEG1 0.99 MB |
Breathy Voice MPEG1 0.34 MB |
Creaky Voice MPEG1 1.26 MB |
We aimed to apply the anothropomorphic talking robot as the experimental methods of human speech control and as the simulation models for clinical methods for oral and laryngeal area. We also may apply to the speech mechanism for human-friendly robots that have same ambience as human. To realize these application, we want to develop mechanisms further similar to human.
This research has been supported by Grant-in-Aid for Scientific Research (KAKENHI). We would like to express our thanks to all co-researchers ,Kuraray Co, Ltd. ATR, Okino Industries, Ltd., Chukoh Chemical Industries, LTD. and SolidWorks Japan K. K. for helping us to develop the robot's hardware.
 Japan Science and Technology Agency (JST)
Japan Science and Technology Agency (JST)